


UPDATE (15/3/2021): I changed the format of the devlog slightly:
- Renamed 'Progress Made' as 'Progress Highlights'
- Removed 'What I did well?' section due to redundancy (what I progressed is generally also what I did well in)
- Added 'Lessons Learnt' section
Progress Highlights
Completed project class diagram (took us three days to come up with it due to problems of visualising ML modules in the diagram)
Finalised use case diagram after 5 amendments (changes to use case decompositions and consolidation of use cases with include relationship)
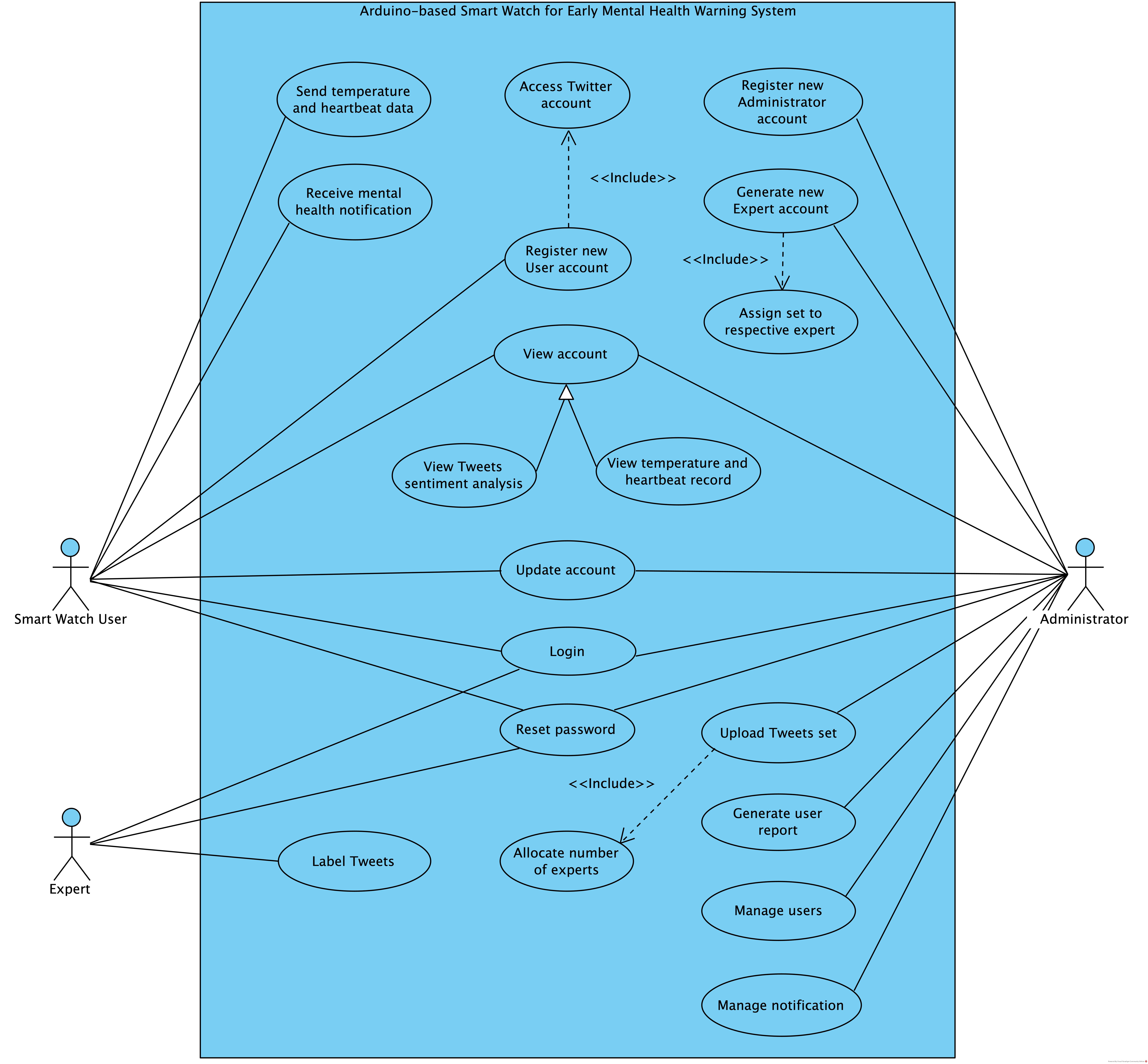
Updated HTA diagram (revamped HTA diagram into users perspective and separated modules from functions)
Finalised list of potential stakeholder/collaborators and submitted to supervisor
Confirmed our stakeholders for FYP! 🥳
Created a brand name and logo for FYP (Fitweet) using a free online logo maker, inspect element (to remove watermark 🤭) and a bit of Photoshop (Each bubble represents a tweet, while the bubbles altogether resemble a brain which represents mental health)

Applied for Twitter Developers account to access Twitter API and got it approved (after writing a long-ass email to them detailing about my FYP)
Successfully developed a simple Python code to extract Tweets (excluding replies, retweets, mentions) with filtration/cleaning techniques (remove links, mentions, demojise emojis into text)
Extracted a total of 50,000 tweets (yes, you read that right) in a span of 2 days
Attended our 2nd meeting with our supervisor (presented progress for Week 2)
What I'm stuck at?
- Still a bit blur about ML process in general (unfamiliar with technical jargons)
- Not sure on the next step of the ML process which is filtering and labelling
How will next week be?
- Temporarily halt work on the emotion detection model to focus on literature review
- First meetings and presentations with two stakeholders (Mdm. Sharifah from UNISEL and CEO of Petrosea)
- Research on Related Works on Detecting Mental Health on Bilingual Twitter Posts for literature review
- Work with Faidz on the Chapter 1 (Introduction) of the FYP1 report (Problem Background, Project Objectives, Project Rationale, Scope and Limitation, Thesis Organisation)
Lessons Learnt
- Networking is super helpful (shoutout to seniors: Melvin, Arina and my internship supervisor Jason Chao)
- Twitter API is dope AF!
- Using web scrapers such as Selenium is against Twitter's Terms of Service. You'd be better off using the official API as the data is much more rich, and you're less likely to have your IP blocked.
- You can only get a maximum of 200 tweets in one request. However, you can make successive requests for older tweets. The maximum number of tweets that you can get in a timeline is 3200.
- User timelines belonging to protected users may only be requested using Twitter API when the authenticated user either "owns" the timeline or is an approved follower of the owner.
- While drafting use case diagram, rule of thumb is to not decompose the use cases too much (e.g: using too many include/generalisation relationships) as use case diagram is supposed to depict a high-level view of the system. Instead, consolidate them and explain in detail inside the use case description.