


Progress Highlights
Researched more than 20 journal articles and conference papers for literature review for Related Works On Detecting Mental Health On Bilingual Twitter Posts
Extended the functionalities of the existing Tweets extractor developed by adding features to extract details from user's followings and followers list
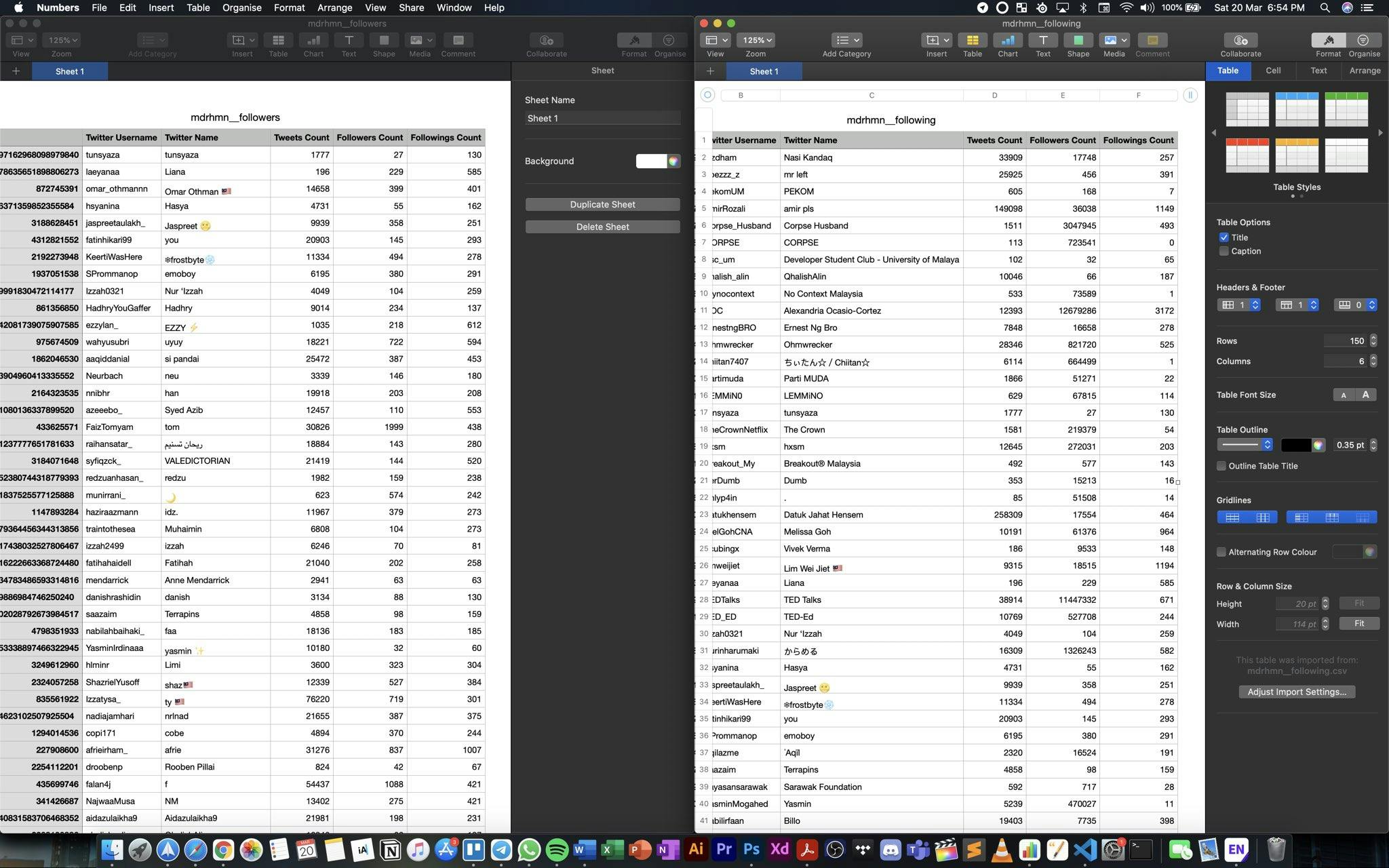
Discovered a new method to extract Tweets without using Twitter API (using Twint package) which has no rate limit(!) and allows you to extract all Tweets from any public Twitter account
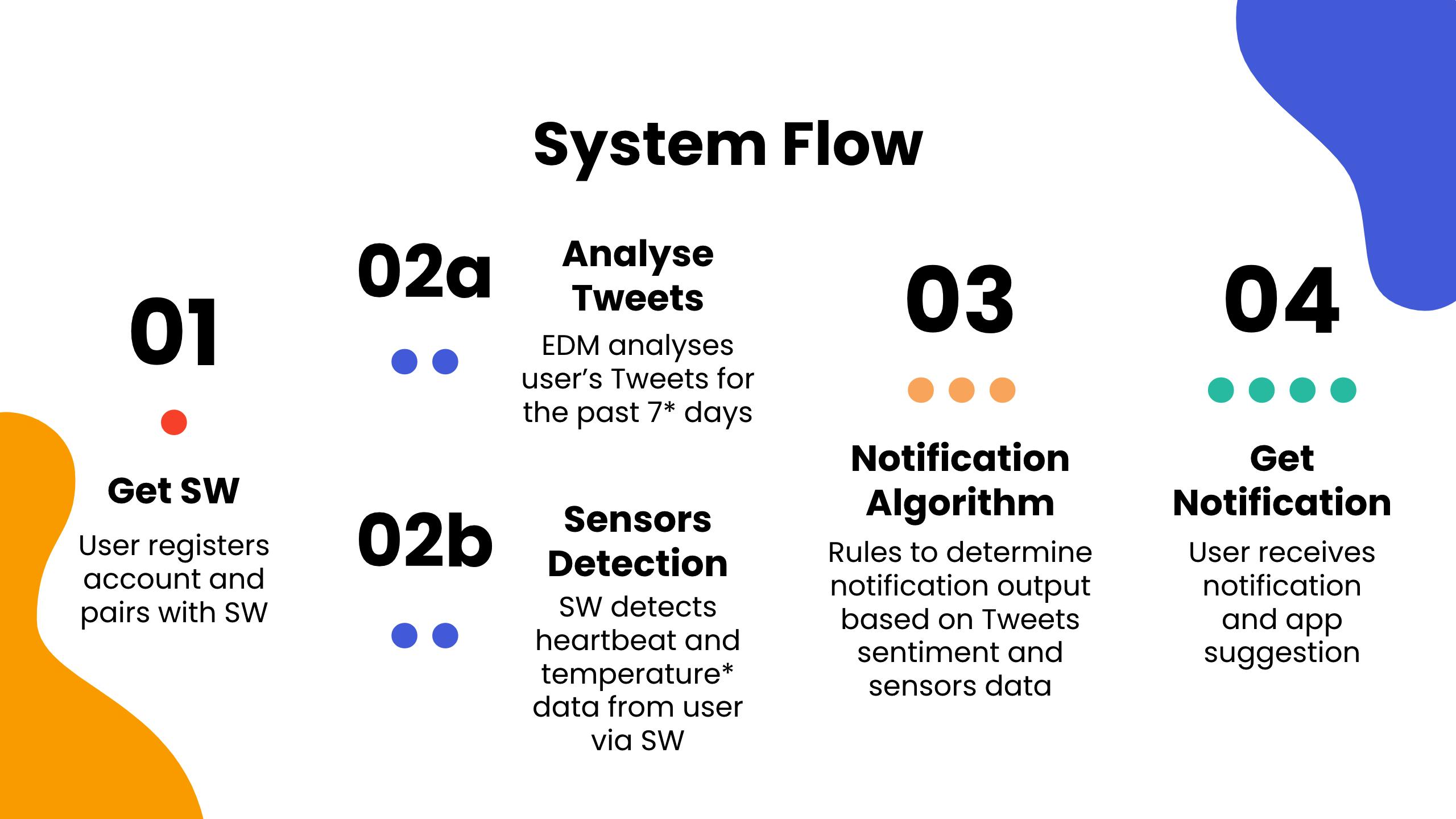
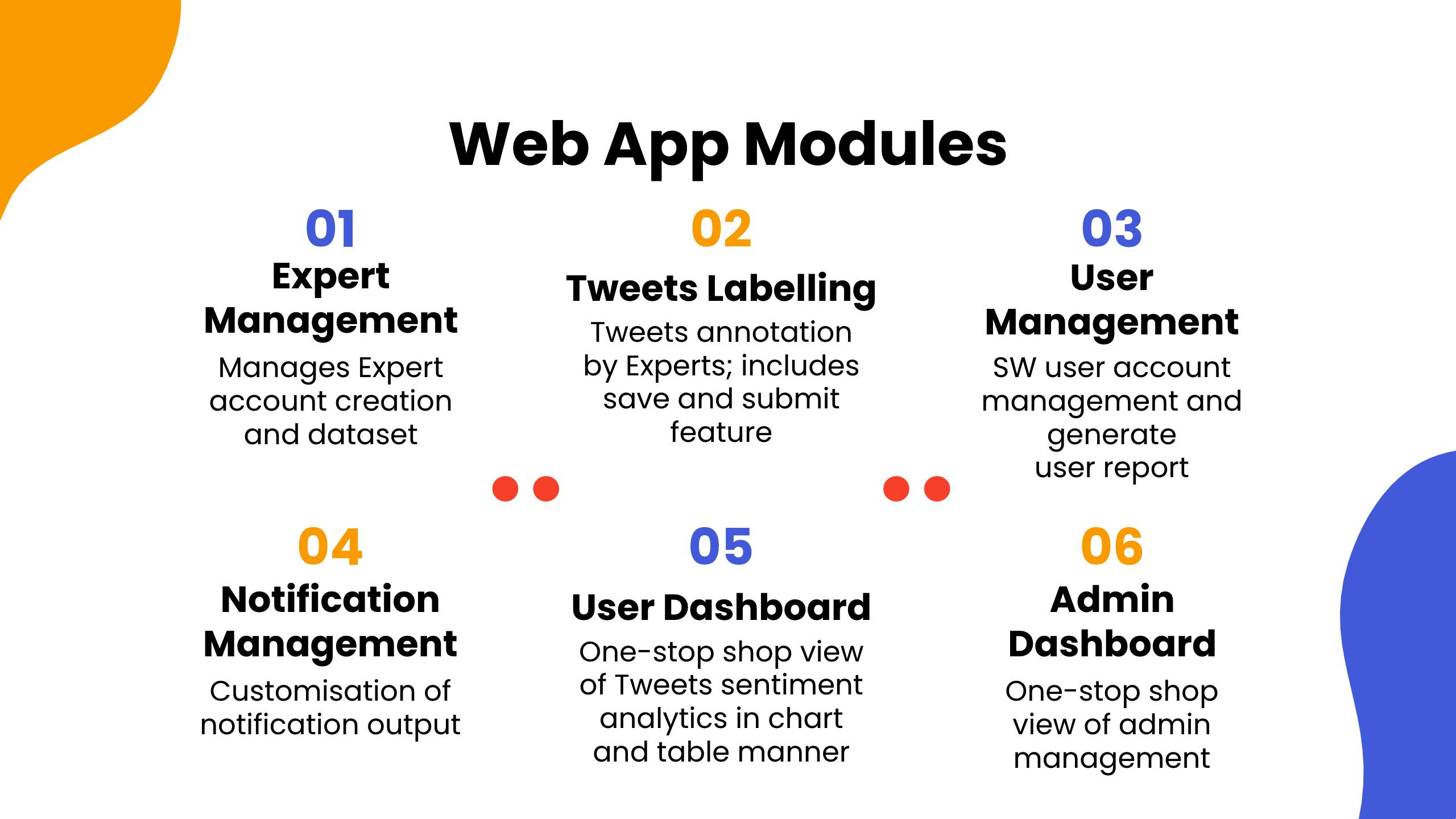
Drafted presentation slides for meetings with two stakeholders (used template from Slidesgo; outlined project flow and web app modules among other things

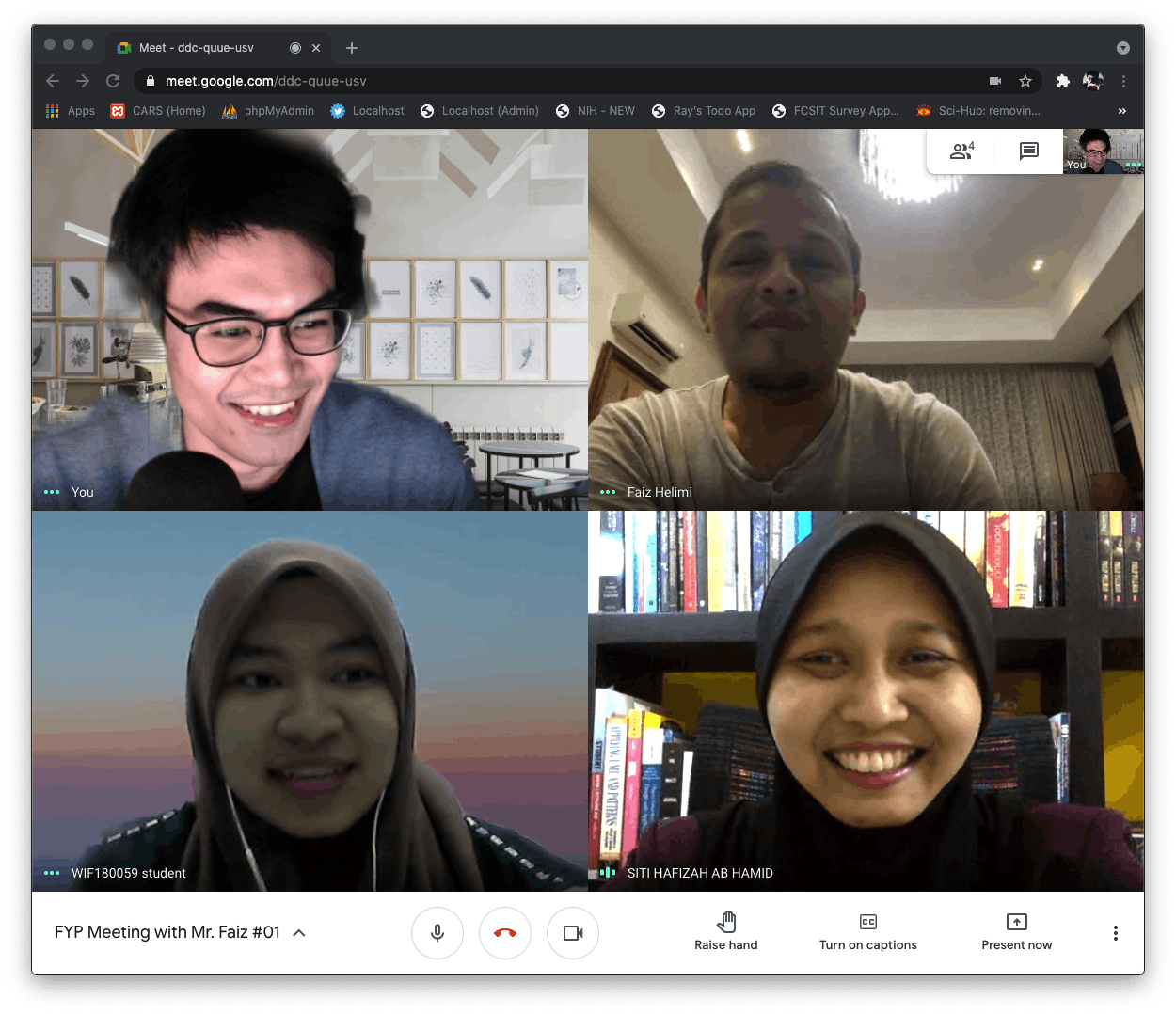
Attended first stakeholder meeting with Mr. Faiz Helimi, CEO of Petrosea Sdn. Bhd. (my Fitweet branding and logo was praised! 🥳)
Completed first draft of Chapter 1: Introduction for FYP1 Report (Introduction, Problem Background, Project Objectives, Project Rationale, Scope and Limitation and Thesis Organisation)
Attended FYP Sharing Session organised by PEKOM to obtain tips for FYP (shout-out to Jia Xiong for his advices on SE!)
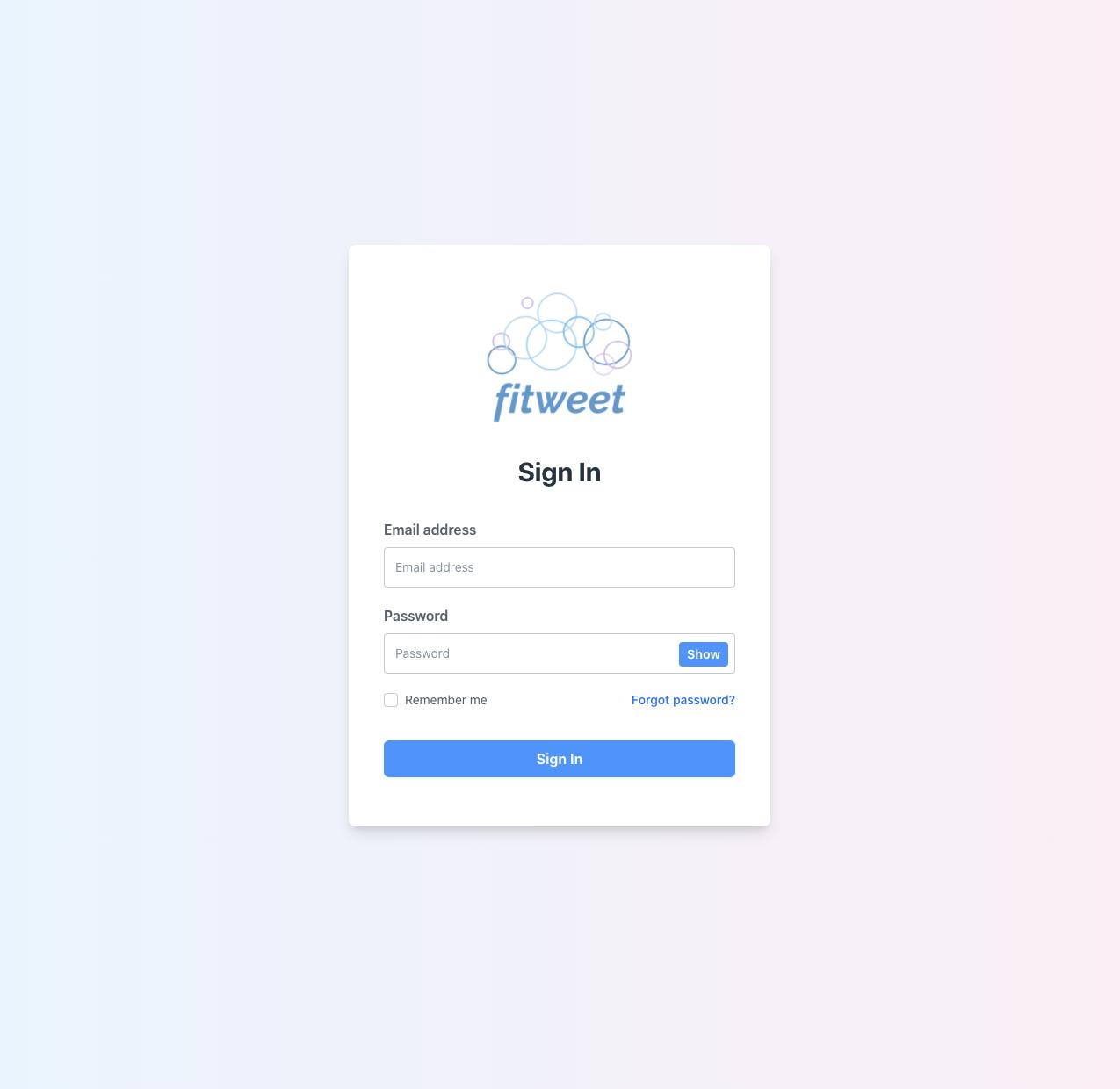
Completed UI design and coding for Log In page using Tailwind CSS integration in Django (includes Show/Hide password functionality)
What I'm stuck at?
- Drafting Table of Comparison on Related Works for Literature Review (supervisor requested to include language, programming language for development, epoch, feature extraction method, ground truth or rules for decision, context of tweets etc.; mostly jargons that I still have no idea what they mean 😓)
- Brainstorming ways to implement other modules of the Labelling Web App (completion due-date set by supervisor: Week 8 or approximately 1 month from now 😰)
- Trying to find the remaining 50+ public Twitter accounts of university students to achieve the 100,000 Tweets extraction target
How will next week be?
- Complete the Table of Comparison on Related Works for Literature Review
- Submit Chapter 1: Introduction draft of FYP1 Report to supervisor for checking
- Begin drafting the high-level UI/UX mock-up of the labelling system using Adobe XD
Lessons Learnt
- Sometimes the first solution you encountered might not be the best one, so don't just stop there as there might be a better and more efficient alternative. For example, I thought the Twitter API will be the only viable method to extract Tweets. As it turns out, Twint does the job much easier with less restrictions and zero authentication.